데이터 군집화 (Clustering)
데이터 군집화의 순서
1) 데이터 전처리
2) Word Embedding (Word2Vec 연관어 모델 생성)
2-1) 어휘간 유사도 계산
2-2) 시각화
3) Scikit-learn을 이용한 비계층적 군집화
- 대표적인 비계층적 군집화 알고리즘인 kMeans 를 사용해 실습
예제1) 네이버 영화 리뷰 데이터를 불러와서 불용어 처리 후, 토큰화 하기
조건)
- 사용패키지: Kiwi, Stopwords, tqdm (리뷰별 토큰화할때)
- 데이터 셋 : data_set\\ratings.txt
- 데이터 개수 : 1000개 리뷰만
- 지정 불용어 사전 만들기 : 불용어사전 = ['저','노라노','거','듯','서','위']
- 3개 문장의 토큰만 추출해보기
결과)
[[], ['디자인', '학생', '외국', '디자이너', '전통', '발전', '문화', '산업', '나라', '시절', '끝', '열정', '전통', '꿈', '감사'], ['폴리스 스토리', '시리즈', '뉴', '하나', '최고']]코드)
#텍스트 불러오기
f = open('data_set\\ratings.txt', 'r', encoding ='utf 8')
raw = f.readlines()
reviews = []
for i in range(1, len(raw)):
reviews.append(raw[i].split('\t')[1])
print(reviews[:3])
#형태소 분석
from kiwipiepy import Kiwi
from kiwipiepy.utils import Stopwords
from tqdm import tqdm
kiwi = Kiwi()
stopwords = Stopwords()
stopwords_add = ['저','노라노','거','듯','서','위'] #불용어 사전 추가
reviews_tokens=[]
for review in tqdm(reviews[:1000]):
token = kiwi.tokenize(review, stopwords=stopwords)
review_token = []
for t in token:
if (t.tag[0]=='N') & (t.form not in stopwords_add):
review_token.append(t.form)
reviews_tokens.append(review_token)
print(reviews_tokens[:100])
예제2-1) 1)에서 만들어진 토큰화된 리뷰를 활용하여 연관어 검색 모델을 만들고 (Word Embedding : Word2Vec) , 벡터 시각화 모듈은 TSNE를 이용하여 (x,y) tuple 데이터를 데이터프레임 형태로 표현하기(단, x축 기준 오름차순으로)
조건)
- 토큰화된 리뷰 변수명 : reviews_tokens
- 사용 함수: Word2Vec 모듈의 gensim.models 함수, TSNE 모듈의 sklearn.manifold 함수
- 연관어 검색결과 추출하기 : '영화' 와 관련도가 높은 10개의 단어 추출
결과)
# 영화와 관련도가 높은 10개 단어
['연출', '굿', '감독', '코믹', '평점', '결말', '노래', '사랑', '주인공', '시리즈']
# TSNE를 이용하여 벡터시각화한 결과를 데이터프레임으로 나타내기

코드)
#Word2Vec (Word Embedding Model) 생성
from gensim.models import Word2Vec
from sklearn.manifold import TSNE
#토큰화된 리뷰 불러오기
word2vec = Word2Vec(reviews_tokens, min_count=5) #min_count: 단어의 최소 빈도수 (5개 이상 나오는 토큰들만 학습)
# 특정 단어와 유사한 단어 추출
sim = word2vec.wv.most_similar('영화', topn=10)
topn_sim = []
for s in sim:
topn_sim.append(s[0])
print(topn_sim)
# 토큰화된 단어간 유사도를 배열로 표시
# 결과값 : similarity[:1] -> array([[ 6.2310090e-04, 7.6949596e-04, 5.3994791e-03, ..., 6.4751715e-03]], dtype=float32)
# 차원확인: similarity.ndim -> 2
# 행수 확인(행수, 열수) similarity.shape -> tuple (141, 100)
vocab =word2vec.wv.index_to_key
similarity= word2vec.wv[vocab]
#시각화 모듈 tsne실행, 높은 차원의 복잡한 데이터를 저차원으로 축소하는 패키지
# [6.2, 7.6, 5.3][3.4,2.4,3.4]....[1.4,2.4,3.4] 등의 복잡한유사도를 고려, 저차원으로 바꾸어 표현가능
tsne = TSNE(n_components=2) # 2차원 (x,y)으로 바꾸기
transform_similarity = tsne.fit_transform(similarity
#데이터프레임으로 전환
import pandas as pd
df = pd.DataFrame(transform_similarity, index=vocab, columns=['x', 'y'])
df.sort_values(by='x', ascending=True, inplace=True) # x축을 기준으로 오름차순 정렬
df[0:10]
예제2-2) 벡터 시각화하기
조건)
- 사용 모듈 : seaborn, font_manager 및 rc 모듈의 matplotlib함수, matplotlib.pyplot 모듈
결과)

코드)
#시각화
import seaborn as sns
from matplotlib import font_manager as fm
from matplotlib import rc
import matplotlib.pyplot as plt
plt.style.use('default')
map = sns.lmplot(x='x', y ='y', data=df, fit_reg=False)
map.figure.set_size_inches(4.8,3)
plt.show();
예제3-1) Scikit-learn 과 KMeans를 이용한 비계층적 군집화
조건) KMeans를 이용해 비계층적 군집화한 데이터프레임 만들기
- 비계층적 군집화 조건 - 클러스터 수 : 6개, 각 centeroid 별 계산 수 : 10번
결과)
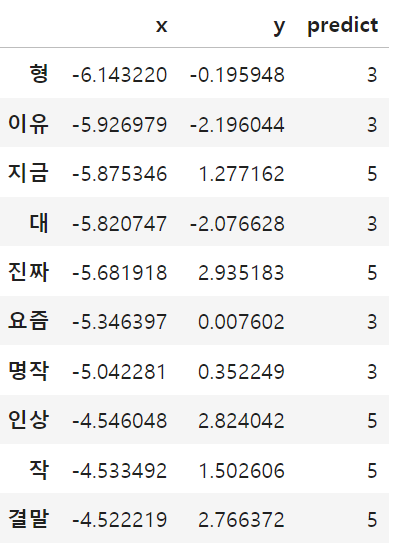
코드)
from sklearn.cluster import KMeans
# 군집 6개, n_init sets the number of initializations to perform.
kmeans = KMeans(n_clusters=6, n_init=10)
#각 값들이 각각 어떤 클러스트에 속하는지 클러스터 인덱스 번호(0~5로 6개) 출력
predict = kmeans.fit_predict(df)
#len(predict) -> 141개
# print(predict)
results = df
results['predict'] = predict
results[:10]
예제3-2) 3-1)의 데이터프레임 결과를 활용하여 가시화하기
조건) 사용패키지 : seaborn
결과)

코드)
import seaborn as sns
map = sns.lmplot(x='x', y ='y', data = results, fit_reg = False, hue ='predict')
map.figure.set_size_inches(4.8,3)
plt.show();